
Open Source on Azure: Dive into Drupal #1
This is the 1st of a 3 part article on exploring Azure, Drupal & DevOps through a new website project for the Hampton Hill Theatre.
The site was due a major facelift and as Drupal 7 EOL is on the horizon, the tech stack needed a complete reboot. So for ease of upgrade and flexibility Drupal 9 was chosen with Azure as the cloud platform.

Drupal is about as open source as you can get for a CMS, it's 100% 🆓, the core code is open (on GitLab & GitHub), API first and has a huge community of developers. It is used across many UK, US and EU governments as well as big name media companies.

Azure is a leading cloud platform from Microsoft, big on security and innovation and has made big inroads into embracing open source technologies. In this case we needed a LAMP stack to support Drupal.
So this small project was perfect opportunity to bring the Theatre's digital presence into the 20's and utilise a DevOps toolchain to deliver the goods!
This is not a step by step coding tutorial on how the site was built but covers the overall approach and will hopefully give you enough insight to generate some useful ideas and inspiration.
The trilogy 👇
- Product backlog: The kick off
- Drupal & DevOps: Choose your weapons
- CI-CD: Rinse & Repeat into Azure
Product backlog: The kick off
In order to get started on any web project we need to create a backlog of things to do and find a decent tool to put it in.
As we are coding and building components we need to track:
- Product backlog
- Source code
- Builds & releases

Enter Azure DevOps (ADO)
Of course the 'One Tool...' does not really exist but in my experience ADO goes a long way to provide everything you need to track software dev in 1 place. Requirements, Wiki, reporting, code and deployments are all integrated and linked to each other.
Added bonus it's 🆓 for first 5 basic license (power) users and has unlimited free stakeholder license access (clients can view & comment on stuff).
Check out this bite-size video from Black Marble.
Build the backlog

Many of us have experienced projects where user stories & requirements are, in theory, saved in a tracking tool (Jira, Pivotal Tracker, Trello, Asana etc) only to be told a stakeholder has 'a private copy' buried away in a spreadsheet, word doc, email or even better...in their head. So it's important to keep it all in 1 accessible place.
Azure Boards in ADO proved an excellent starting point to get all the project aims & objectives transferred from a Google Doc into a 'single source of truth' backlog.
As a Certified Scrum Master (thanks to the brilliant Mike Cohn) I opted for the out of the box scrum process which comes with Epics, Features, Product Backlog Items (PBI), Impediments, Bugs and Tasks. You can fully customise all these work items, fields and values if needed (even create custom processes).
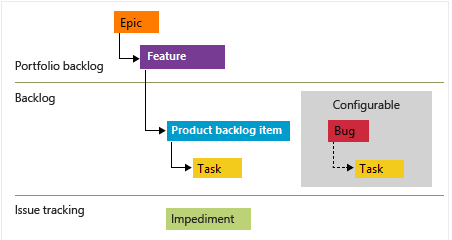
How you slice & dice the backlog is a personal choice for any Scrum Master/Dev Manager/Product owner but starting out with Epics based on Design/Dev/Content/Go Live really helped me plan out the portfolio view of the project.
I broke this down hierarchically with the Feature level e.g Front end, Azure architecture, IaC, Content Types etc but found at times this is not always necessary as you can end up duplicating a feature with a PBI / user story just for the sake of using it. So you could just use Epics & PBI's.
Traversing down into the working backlog (the doing) writing out your PBI's using the User Story syntax ensures it's something your client really needs & wants.
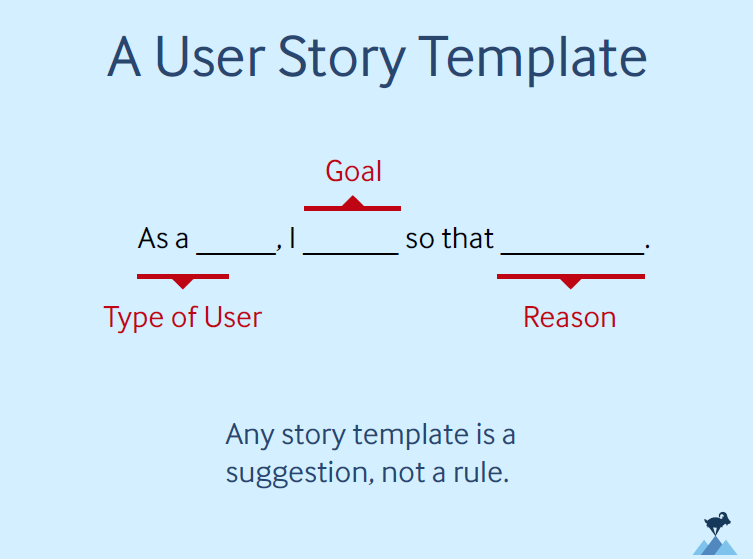
For those new to user stories it's worth checking out this link (only after you've read this blog please 😉):
We're all about Agile so it doesn't matter if you don't have the entire project mapped out yet (in fact don't attempt it). Picking an Epic or 2 to start with should give you enough PBI's to form a first 2 week Sprint. The more granular dev tasks within each PBI can be added later at Sprint planning.
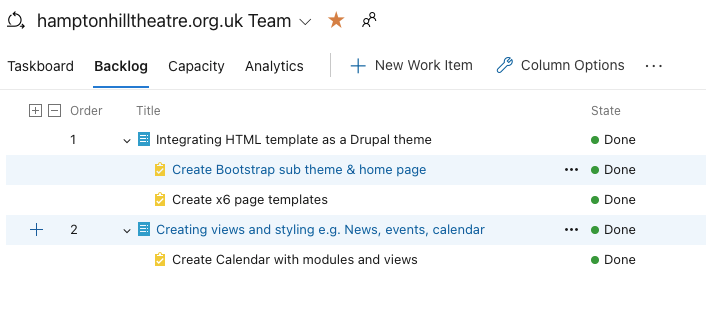
Scrum Master: Top Tip 💡
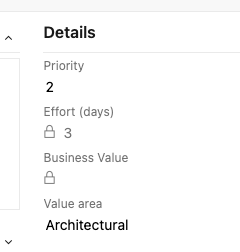
If you want to track time spent on development, estimating the PBI's effort by days and it's sub tasks by hours ensures they correlate and you get back useful reporting metrics.
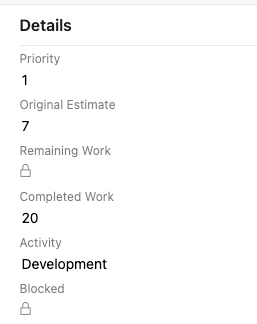
If you like running a tight ship like me, then at the end of each Sprint whip through these with the team:
- Zero out 'Remaining Work' & update hours 'Completed Work' of all DONE tasks
- Update the status of all completed PBI's
- Drag incomplete backlog items and tasks to the next sprint or chuck 'em back in the product backlog
💰 If the project involves billing to a client or project cost code:
- Update timesheet hours based on completed backlog items & tasks
I prefer T-Shirts
If counting & billing exact hours are not as important to you then 'T-Shirt size' can be a very useful concept to help estimate on effort on PBI's with some sense of time attached.
The Story Points field does not ship out of the box with the ADO Scrum process (comes with the Agile process and User Story work item) but you can add it as a custom field and change the values like below.
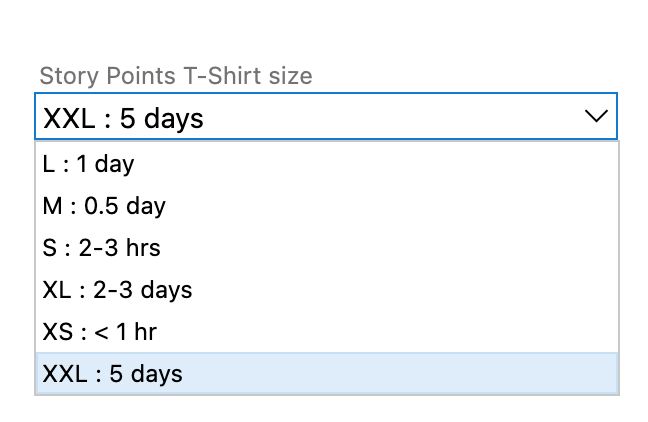
If you want to instead use pure agile 'Story Points' e.g. 0, 1, 2, 3, 5, 8, 13, 20, 40 & 100, that's an excellent way to calculate effort & Sprint velocity so long as your team first gets up to speed on Agile Scrum & Planning Poker.
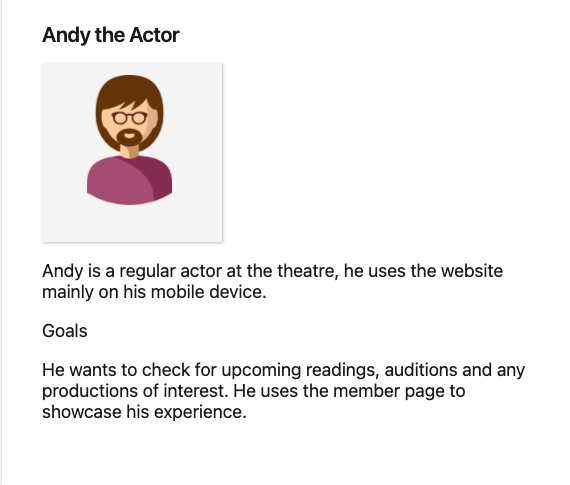
Make it Personal
To fully embrace User Centred Design the ADO Personas extension lets you create Personas and link them to work items so you can focus on the people you are developing for. Helps answer the question - Why are we building this thing!?
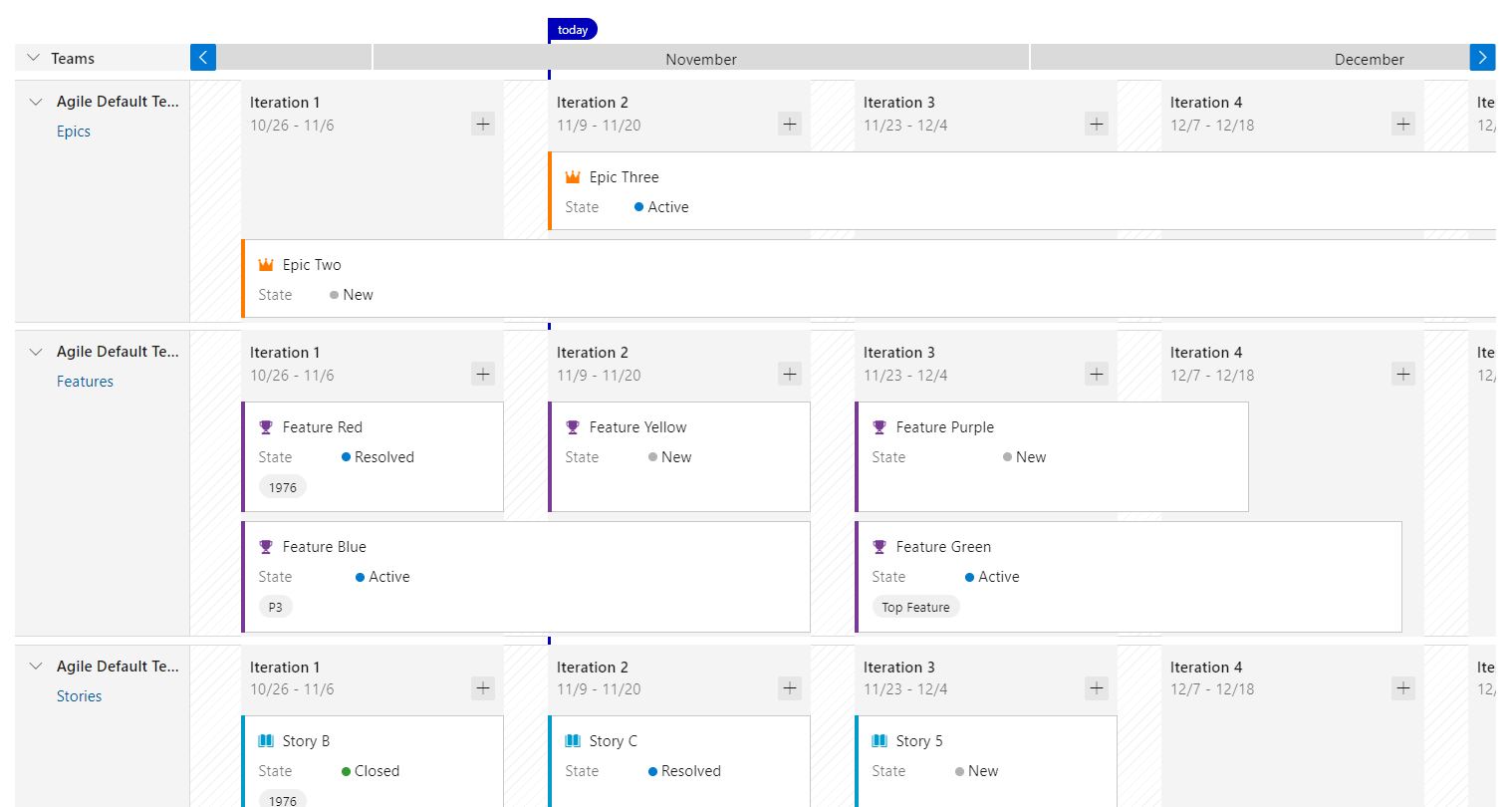
Give me the GANTT
Clients always want dates.
Developers also might want to know when to ship things.
When wearing your project manager hat one of the great new ADO features is Delivery Plans. It creates a timeline making it easy to visualise your end to end backlog and show a helicopter view of what's going down with key dates & milestones.
The timeline relies on start and end dates, so if these have been added to your Epics & Features they will show up, even better your Sprints/Iterations will display so you can see how they slot into the high portfolio level. You can also add dependencies between items.
It is not a full powered Gantt chart but goes along way to bringing project management timelines into ADO, rather than trying to copy it all into something like Project Online.
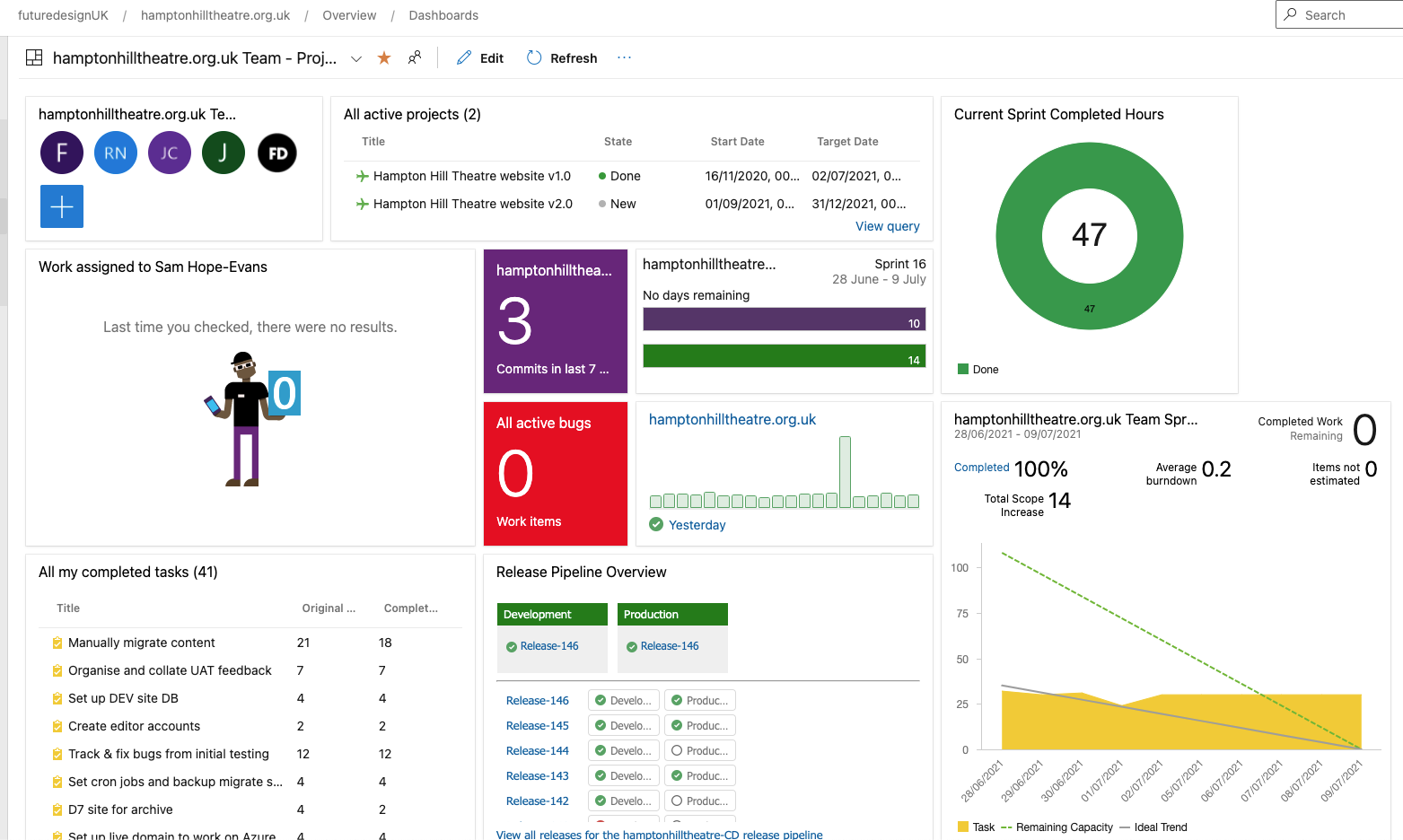
The big picture
As we now have all this data in the backlog ready to go we need to report on things. ADO has rich out of the box reporting tools with in built queries to interrogate your data as needed.
Using these queries and extensions you can build dashboards that are Information Radiators, showing everything going on in the project, from team members, overdue/blocked tasks, code commits, pipeline status through to Azure cloud spend.
Wrap up
That's it for part 1, hope that was useful. A big focus there on Azure DevOps and how it's a great tool to kick off your project & backlog.
It has to be said both GitHub and GitLab are enhancing their Issue tracking to get closer parity to Azure boards so watch this space!
Please check out part 2 where we get much more technical in Drupal & DevOps: Choose your weapons - see you then!


